 第24期 - 硬核的大模型项目
第24期 - 硬核的大模型项目
本期介绍几个超硬核的大模型开源项目,涵盖声纹识别、推理引擎、搜索能力训练、音频生成等。
Ai周刊:关注 Python、机器学习、深度学习、大模型等硬核技术
本期目录:
- 1、LLM Finetuning Notebooks
- 2、3D-Speaker
- 3、KsanaLLM
- 4、ZeroSearch
- 5、ThinkSound
- 6、MaskSearch
- 7、LMCache
- 8、Langflow
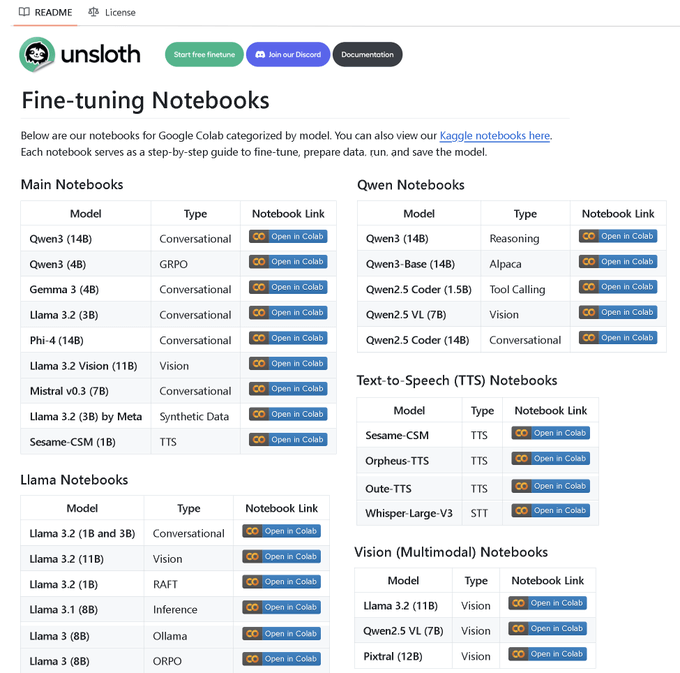
1、LLM Finetuning Notebooks
地址:https://github.com/ml-explore/llm-finetuning
100 多个微调笔记本的代码库,一站式集齐所有资源!
包含以下指南和示例: • 工具调用、分类任务、合成数据生成 • BERT 模型、文本转语音(TTS)、视觉大语言模型 • GRPO、DPO、SFT、CPT • 数据预处理、评估、保存 • Llama、Qwen、Gemma、Phi、DeepSeek
2、3D-Speaker
地址:https://github.com/modelscope/3D-Speaker
![]()
3D-Speaker 是一个开源工具包,专注于单模态和多模态的声纹验证、识别和日志(diarization)。它由 ModelScope 社区孵化,旨在为开发者和研究者提供一套全面、强大且易于使用的声纹处理解决方案。
核心功能与特点:
- 多任务支持:该工具包不仅支持传统的声纹验证(判断两段语音是否来自同一个人)和识别(从众多说话人中识别出特定的一位),还支持说话人日志功能,能够切分出一段语音中不同说话人的片段。
- 多模态能力:除了处理纯音频信号,3D-Speaker 还具备多模态处理能力,可以结合视频信息(如唇动)来进行更精准的声纹分析。
- 丰富的预训练模型:项目在 ModelScope 上发布了所有预训练模型,这些模型基于大规模数据集训练,包括一个名为 3D-Speaker-Dataset 的大规模语音语料库,极大地推动了语音表征解耦的研究。
- 业界领先的性能:该项目在多个知名声纹识别基准数据集(如 VoxCeleb, CNCeleb)上都取得了领先的性能指标(EER)。
无论是需要构建一个会议记录系统,还是开发智能客服的声纹验证功能,3D-Speaker 都提供了一个坚实的基础。
3、KsanaLLM
地址:https://github.com/Tencent/KsanaLLM/blob/main/README_cn.md
KsanaLLM(一念 LLM)是腾讯推出的一款面向大语言模型(LLM)推理和服务的高性能、高易用性推理引擎。它旨在解决 LLM 服务中常见的性能瓶颈,提供极致的推理速度和吞吐量。
核心优势:
- 极致性能:通过集成 vLLM、TensorRT-LLM 等业界顶尖框架的高性能 CUDA 算子,并结合 PagedAttention 等先进技术,实现了高效的显存管理和计算优化。
- 高吞吐动态批处理:引擎对任务调度和显存占用进行了精细调优,支持动态批处理(Dynamic Batching)和前缀缓存(Prefix Caching),能够在不牺牲延迟的情况下,大幅提升并发处理能力。
- 广泛的硬件和模型支持:KsanaLLM 不仅在 NVIDIA A10/A100/L40 等主流 GPU 上经过了充分验证,还创新性地支持华为昇腾(Ascend)NPU,展现了其强大的硬件兼容性。同时,它无缝支持 LLaMA、Baichuan、Qwen、Yi、DeepSeek 等众多主流的开源大模型。
- 灵活易用:提供与 OpenAI 兼容的 API 服务,支持流式输出、多卡张量并行等高级功能,并且可以轻松集成 Hugging Face 模型生态,极大方便了开发者进行部署和二次开发。
对于需要部署高性能、高并发 LLM 服务的企业和开发者来说,KsanaLLM 提供了一个极具吸引力的开源解决方案。
4、ZeroSearch
地址:https://github.com/Alibaba-NLP/ZeroSearch
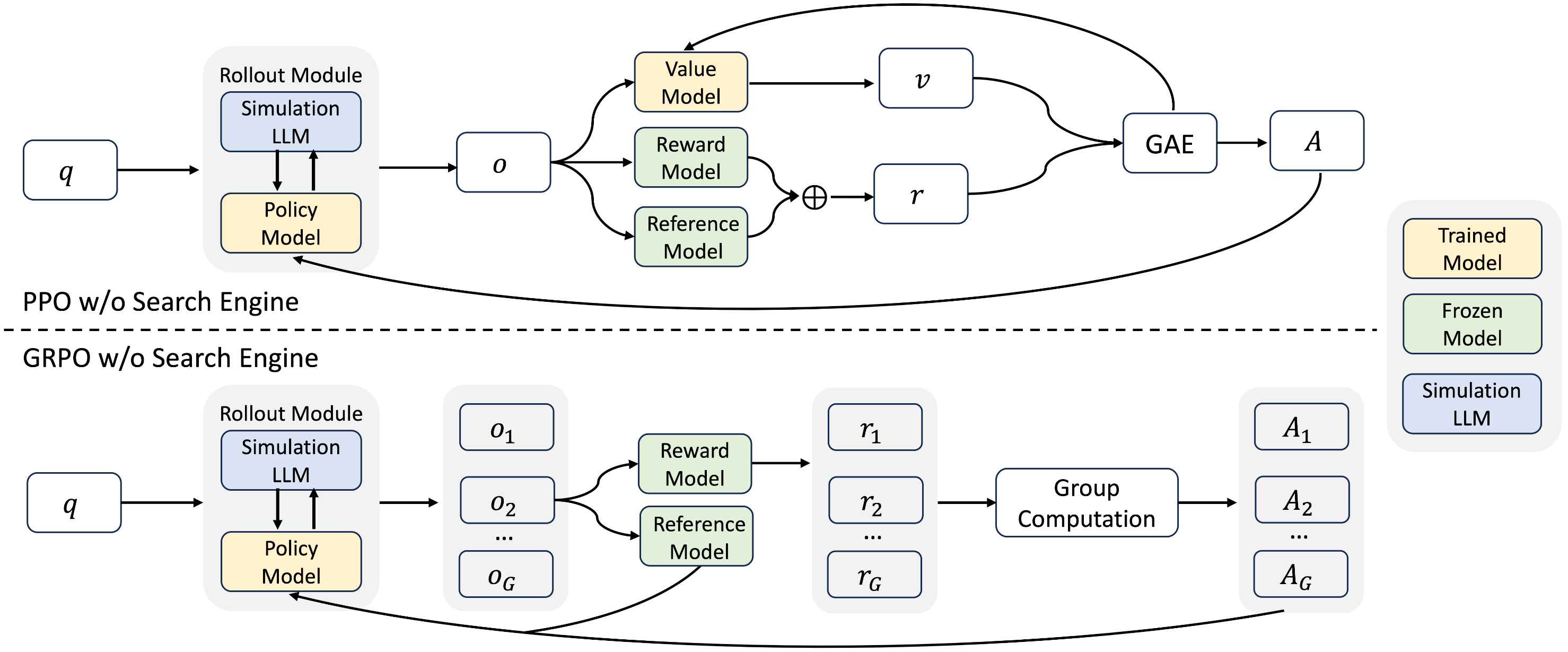
ZeroSearch 是阿里巴巴通义实验室提出的一种新颖的强化学习(RL)框架,其核心思想是 “在不进行真实搜索的情况下,激励大语言模型(LLM)使用搜索引擎的能力”。
传统的 LLM 搜索能力训练方法通常依赖于与真实搜索引擎(如 Google、Bing)的实时交互,但这面临两大挑战:
- 不可控的文档质量:搜索引擎返回的文档质量参差不齐,给训练过程带来噪声和不稳定性。
- 高昂的 API 成本:强化学习需要大量交互训练,可能产生数十万次搜索请求,导致高昂的 API 费用。
ZeroSearch 的创新之处:
它通过一个巧妙的“模拟”策略来解决以上问题。首先,通过轻量级的监督微调(SFT),将 LLM 本身转变为一个“检索模块”,使其能够根据查询生成“有用”和“有噪声”的文档。
在强化学习训练阶段,ZeroSearch 采用一种基于课程学习的策略,逐步增加模拟搜索结果的“噪声”,从而由易到难地激发和锻炼模型进行信息甄别和推理的能力。
核心优势:
- 零 API 成本:整个训练过程在模拟环境中完成,完全无需调用外部搜索引擎 API。
- 性能超越:实验结果表明,ZeroSearch 在多个数据集上的表现优于基于真实搜索引擎训练的模型。
- 良好的泛化性:该框架适用于不同参数规模的基础模型和指令微调模型,并支持多种强化学习算法。
对于希望提升 LLM 在复杂问答、推理等场景下信息获取和利用能力的开发者来说,ZeroSearch 提供了一个低成本、高效率的创新训练范式。
5、ThinkSound
地址:https://openaitx.github.io/view.html?user=FunAudioLLM&project=ThinkSound&lang=zh-CN

ThinkSound 是一个统一的、支持任意模态到音频(Any2Audio)的生成框架,其独特之处在于它由“思维链(Chain-of-Thought, CoT)”推理来引导整个音频生成过程。
想象一下,你不仅可以告诉模型“为这段视频配上声音”,还可以像导演一样,通过点击视频中的某个物体来“增强这个物体的声音”,或者用一句话来“让雨声更大一些”。ThinkSound 就致力于实现这种智能、可控、可交互的音频生成体验。
核心方法与特点:
ThinkSound 将复杂的音频生成与编辑任务分解为三个交互式阶段,全程由多模态大语言模型(MLLM)的思维链推理进行指导:
- 拟音生成(Foley Generation):从视频中生成与语义和时间线都对齐的基础音景。
- 对象中心优化(Object-Centric Refinement):通过点击视频中的物体或区域,为用户指定的对象优化或添加声音。
- 目标音频编辑(Targeted Audio Editing):使用高层次的自然语言指令来修改已生成的音频。
主要优势:
- 多模态输入:支持从视频、文本、图像等多种输入生成音频。
- 可控与可组合:通过思维链引导,用户可以对音频内容进行精细的控制和组合。
- 交互式编辑:支持点击视觉对象或使用文本指令来编辑特定的声音事件。
- 统一框架:一个基础模型即可支持生成、编辑和交互的完整工作流。
对于视频创作者、游戏开发者或任何需要进行创意音频设计的用户来说,ThinkSound 提供了一个极具想象力和实用性的工具。
6、MaskSearch
地址:https://github.com/Alibaba-NLP/MaskSearch

MaskSearch 是阿里巴巴团队在提升大模型搜索能力方向上的又一力作。它提出了一个通用的预训练框架,旨在从根源上增强 Agent 的通用搜索能力。
如果说 ZeroSearch 是通过“模拟考试”来训练学生,那么 MaskSearch 就像是设计了一套全新的“完形填空”教材,让模型在海量的预训练数据中学会如何通过检索工具来补全信息。
核心思想与方法:
- 检索增强掩码预测(RAMP):这是 MaskSearch 提出的核心预训练任务。具体来说,模型会在大量的预训练文本中遇到被“掩盖”(Mask)掉的部分,它的任务就是学习如何主动使用搜索工具来查找信息,并用找到的信息来填补这些空白。这个过程极大地锻炼了模型在各种场景下的信息检索和推理能力。
- 高质量数据生成:为了支撑 RAMP 任务,MaskSearch 采用了一种“多 Agent 系统” + “自进化教师模型”的复杂流程来生成高质量的训练数据。这个系统包含规划器、改写器、观察者等多个角色,协同工作,确保训练数据的质量和多样性。
主要优势:
- 通用性:作为一个预训练框架,MaskSearch 旨在提升模型的“底层能力”,因此其增强效果可以泛化到各种下游的搜索和问答任务中。
- 性能显著提升:大量实验证明,经过 MaskSearch 预训练的模型,在领域内和领域外的下游任务中都表现出显著的性能提升。
MaskSearch 为如何将“搜索”这一关键能力更原生、更深入地融入大模型提供了一个全新的、富有成效的思路。
7、LMCache
地址:https://github.com/LMCache/LMCache

LMCache 是一个为大语言模型(LLM)服务引擎设计的扩展,旨在显著降低长上下文场景下的“首字返回时间”(TTFT)并提升吞吐量。
在多轮问答、RAG(检索增强生成)等常见应用中,输入给模型的提示(Prompt)中往往包含大量重复内容(例如,历史对话、检索到的文档块等)。传统推理引擎每次都需要对完整的提示进行计算,浪费了宝贵的 GPU 资源。
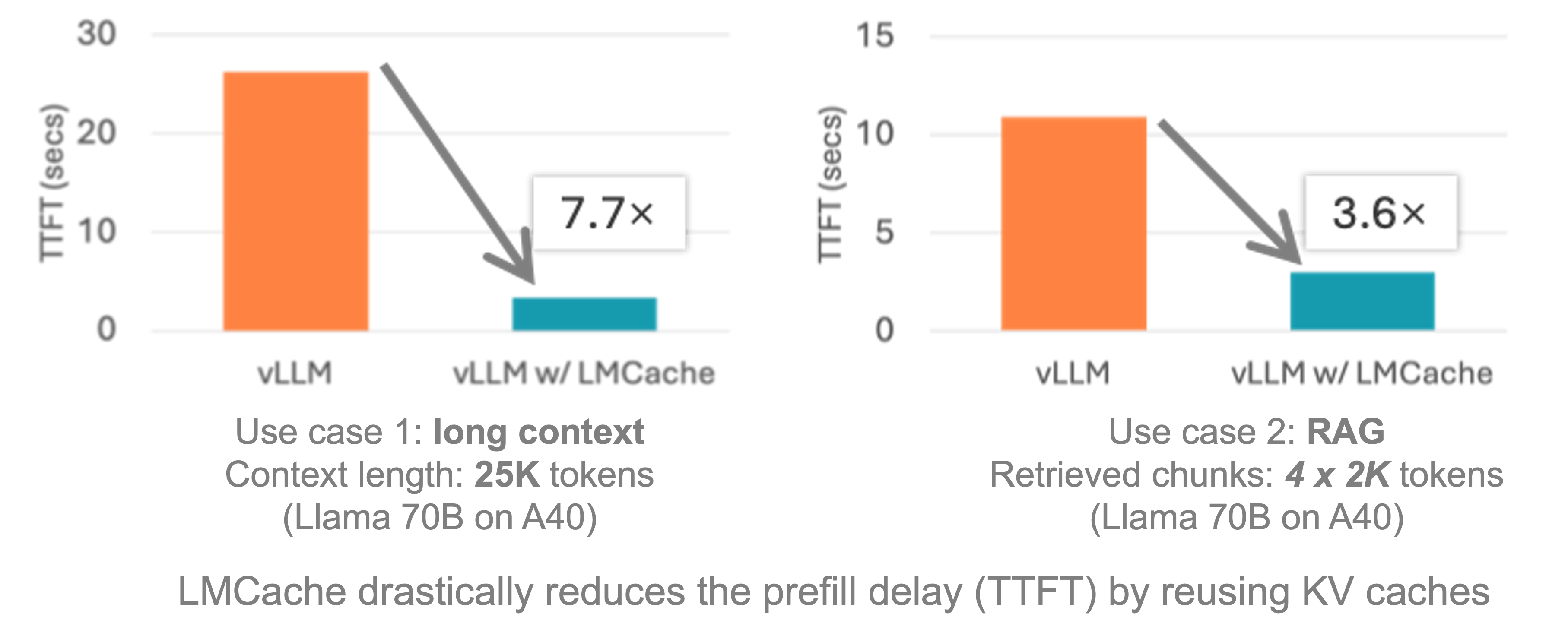
LMCache 的核心创新:
LMCache 通过智能地缓存和复用这些文本块的 KV Cache(键值缓存,Transformer 模型中的一种中间计算结果)来解决这个问题。其最关键的特性是:
- 任意位置复用:不同于只能复用“前缀”的传统缓存技术,LMCache 能够识别并复用出现在提示中任意位置的重复文本所对应的 KV Cache。
- 多级存储:它可以将缓存存储在 GPU 显存、CPU 内存甚至本地磁盘上,灵活地平衡成本与效率。
- 跨实例共享:缓存甚至可以在多个不同的推理服务实例之间共享,进一步提升了缓存的命中率和整个集群的效率。
效果与集成:
通过与 vLLM 等主流推理引擎结合,LMCache 能够在许多应用场景下带来 3-10 倍的延迟降低和 GPU 计算量节省。它已经被 vLLM Production Stack、KServe 等多个业界知名的开源项目官方支持。
对于追求极致推理性能和成本效益的 LLM 应用开发者来说,LMCache 提供了一个即插即用、效果显著的优化利器。
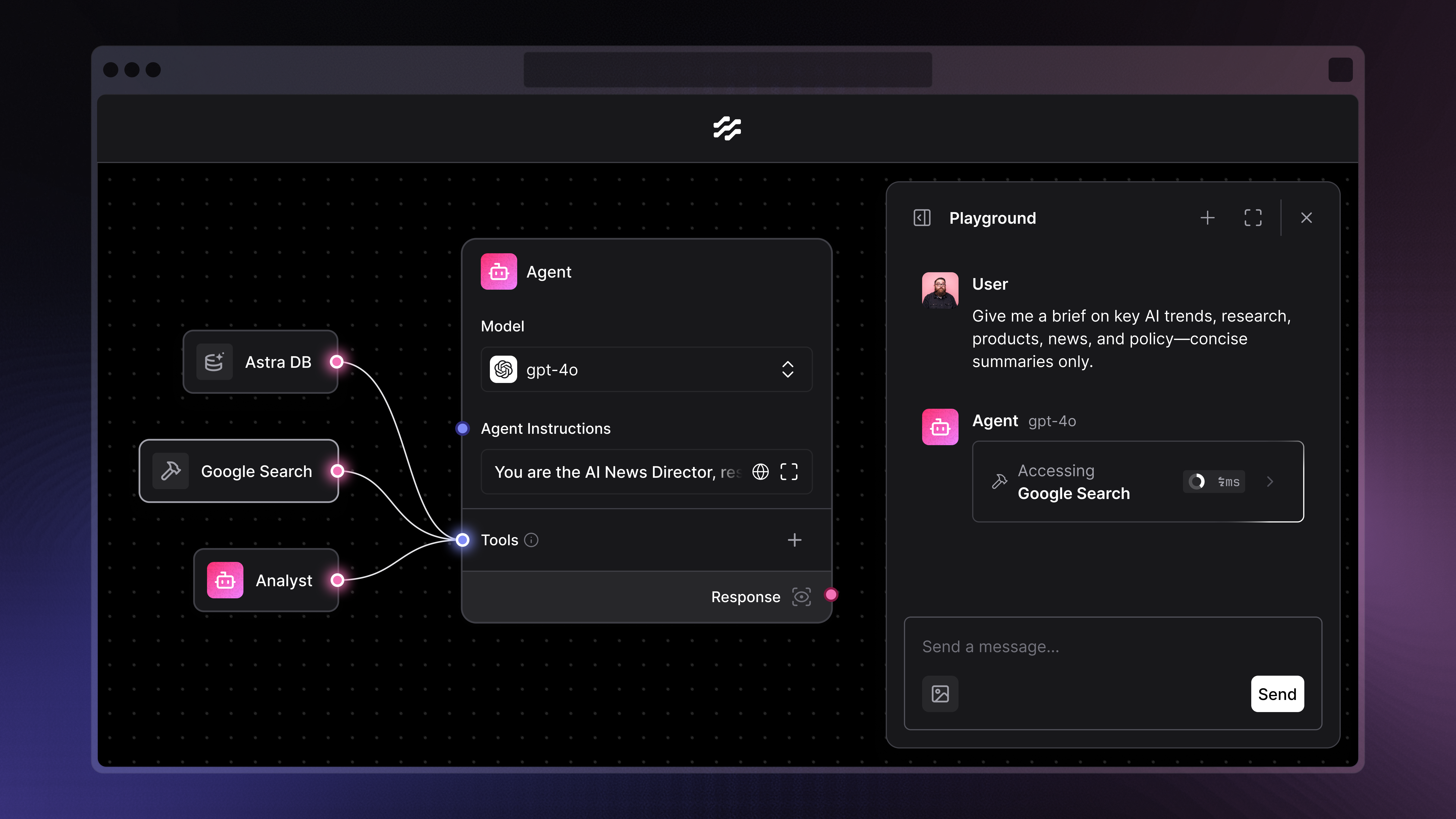
8、Langflow
地址:https://github.com/langflow-ai/langflow
Langflow 是一个为 LangChain 生态系统设计的图形化界面(UI),旨在让开发者能够通过拖拽和连接组件的方式,快速地实验和构建大语言模型(LLM)应用。
如果你觉得用代码一行一行地构建 Agent 和 Chain 显得繁琐和抽象,那么 Langflow 就是为你准备的“可视化编程”利器。
核心功能与特点:
- 可视化构建器:提供一个直观的画布,你可以将 LLM、提示词模板、向量数据库、工具等组件拖拽到画布上,然后像连接电路一样将它们组合起来,构建出复杂的应用流程。
- 快速迭代与测试:内置交互式聊天窗口,让你在构建流程的同时就能立即进行测试和调试,极大地提升了开发效率。
- 一键部署:构建完成的应用流可以一键部署为 API 端点,方便地集成到你现有的应用程序中。
- 代码导出与定制:虽然是图形化界面,但 Langflow 同样支持导出为 Python 代码(JSON 格式),方便你进行更深度的定制或集成到其他项目中。
- 丰富的组件库:内置了对 LangChain 生态中绝大多数主流 LLM、向量数据库和工具的支持,开箱即用。
对于希望快速验证想法、搭建原型或偏好可视化开发的 LLM 应用开发者来说,Langflow 提供了一个优雅且高效的解决方案。
