第11期 - 很小的大语言模型
第11期 - 很小的大语言模型

能在手机上运行的小型语言模型
目录:
1、可视化维基百科
2、Al 贴纸生成网站
3、一个创新的写作系统:STORM
4、能在手机上运行的小型语言模型
5、从健身房到 SaaS 产品
6、AFFiNE:本地的开源 Notion + Miro 解决方案
7、微软最新研究:不经过训练直接融合多个 Lora 不损失效果
8、Morph Studio 与 Stability Al 合作
9、工具推荐:腾讯做了一个在线工具箱
10、软件推荐:LocalSend
11、资料推荐:认知偏差知识手册
12、课程推荐:**Prompt Engineering with Llama 2
1、可视化维基百科
网址: https://explorer.globe.engineer
Globe Explorer 是一款全新的 AI 搜索引擎。不同于传统的搜索引擎,Globe Explorer 提供了更为丰富和个性化的搜索体验,让您轻松发现您感兴趣的内容。不管您对工程、科学、艺术、学校、技术、爱好、生活方式等领域有何需求,Globe Explorer 都能满足您的探索欲望。
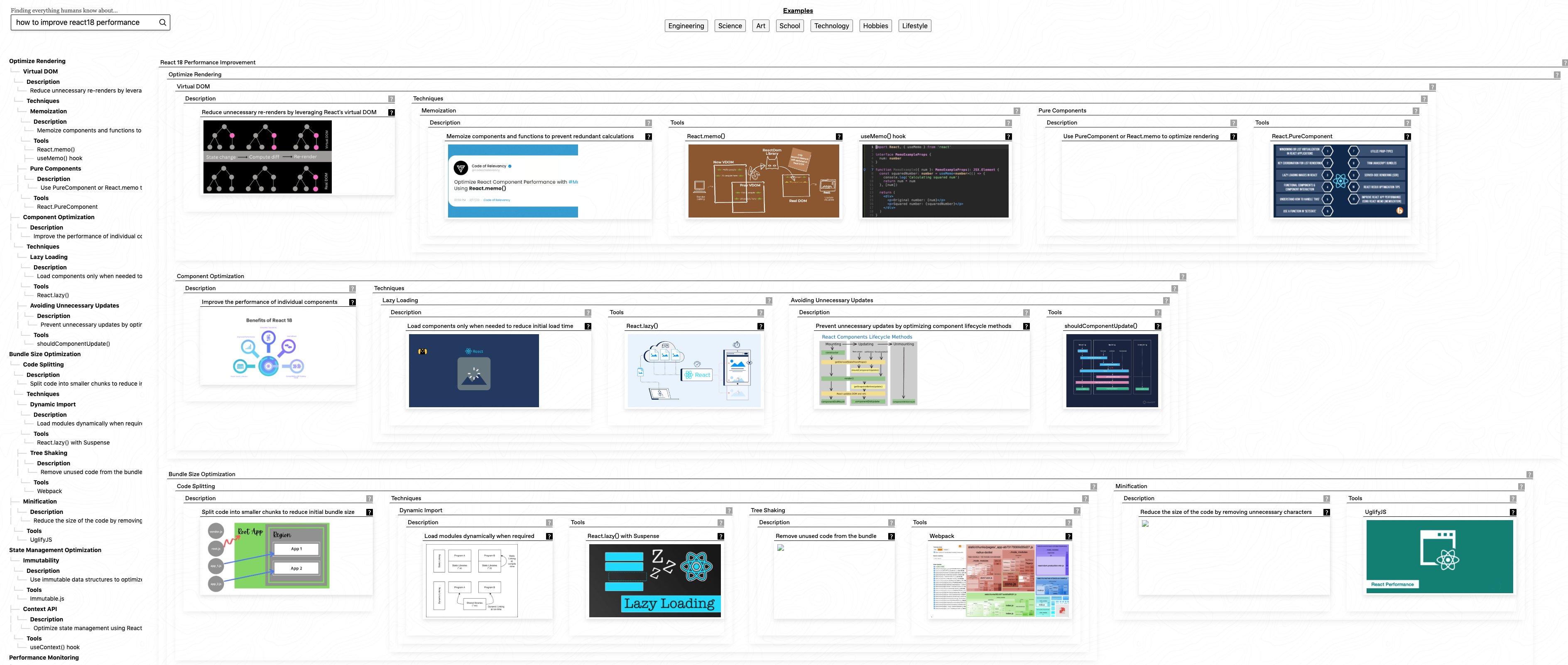
看起来像是可视化的维基百科的工具。这个工具可以帮助用户搜索关键词,并快速整理和组织各种信息,形成一个类似思维导图的结构,让用户能够快速明了地查看他们搜索的信息。
核心功能:
-
个性化搜索体验:Globe Explorer 提供个性化的搜索体验,根据用户的兴趣和需求呈现定制化的搜索结果。
-
多语言支持:除了英文,Globe Explorer 还支持多种语言搜索,让用户能够用最熟悉的语言获取信息。
-
高质量搜索结果:平台致力于提供高质量的搜索结果,满足用户对工程、科学、艺术、学校、技术、爱好、生活方式等领域的需求。
2、AI 贴纸生成网站
有人基于 sticker-maker 开源模型: https://replicate.com/fofr/sticker-maker 做了个 AI 贴纸生成网站: https://stickerbaker.com 作者开源了这个贴纸生成网站的代码: https://github.com/cbh123/stickerbaker
这真是一个模型到应用到开源典范,大家可以试玩一下。
3、一个创新的写作系统:STORM
由斯坦福大学研究人员开发,旨在利用大语言模型自动化从头开始编写具有维基百科一样有广度和深度的长篇文章。
STORM 能自动收集多角度信息并模拟像专家提问的对话过程创建大纲,最终生成带有引文的文本,并逐节撰写完整的文章。
主要挑战和解决方案:
挑战:维基百科样式的文章要求深入研究和计划,包括广泛收集参考资料和精心制作大纲。现有的生成维基百科文章的工作往往绕过了这一写作前阶段。
解决方案:STORM 通过模拟人类写作过程中的预写、起草和修订阶段,特别是在预写阶段,通过有效的问题提问来自动化这一过程。
STORM 的工作流程:
1、发现不同视角:STORM 首先通过检索和分析与给定话题相似的维基百科文章,从多个来源和角度探索话题,以确保内容的全面性和深度,发现研究话题时的多样视角。
2、模拟对话:接着,系统模拟作家向话题专家提出问题的对话过程。这一步骤使用 LLMs 生成深入的问题,目的是从不同的视角深化对话题的理解。这些对话基于互联网上的可信资源。
3、创建大纲:基于收集到的信息和提出的问题,STORM 自动创建文章的大纲。这个大纲旨在组织文章结构,确保内容覆盖广度和深度。
在最后的写作阶段,STORM 生成带有引文的文本,并逐节撰写完整的文章。
STORM 系统旨在解决以下主要问题:
1、写作前研究的自动化:在传统的长篇文章写作过程中,写作前的研究(包括话题研究、信息收集和大纲制作)是一项耗时且复杂的任务。STORM 通过自动化这一过程,帮助作者高效地收集和组织所需的信息,从而提高写作效率。
2、多视角信息的整合:对于任何给定话题,从不同的视角探索和理解信息是产生全面且深入文章的关键。STORM 通过模拟对话式问题提问,自动从多个视角收集和整理话题相关信息,确保文章内容的全面性和深度。
3、生成结构化的文章大纲:一个清晰、有逻辑的文章大纲是高质量写作的基础。STORM 系统创新地利用检索到的信息和提出的问题自动创建大纲,帮助作者在写作过程中保持组织性和目标明确。
4、提高文章质量:通过上述自动化的写作前研究和大纲制作过程,STORM 旨在生成组织性更强、内容覆盖更广的文章,从而直接提高最终文章的质量。
评估结果:
FreshWiki 数据集:为了评估 STORM 系统,研究团队创建了 FreshWiki 数据集,这是一个包含最新高质量维基百科文章的数据集,用于测试系统生成文章的质量。
大纲质量评估:通过专家评审和自动化评估方法,STORM 生成的大纲在组织性和覆盖广度方面表现优异,相比于基线模型,显示出显著的改进。
写作质量提升:相比于基于大纲驱动的检索增强基线生成的文章,STORM 生成的文章在组织性(绝对增加了 25%)和覆盖广度(增加了 10%)方面表现更佳。
专家反馈:经验丰富的维基百科编辑的反馈也证实了 STORM 在生成有根据的长篇文章方面的有效性,并指出了未来改进的方向,如源偏见转移和不相关事实的过度关联问题。
论文:https://arxiv.org/abs/2402.14207 PDF:https://arxiv.org/pdf/2402.14207.pdf
4、能在手机上运行的小型语言模型
该模型基于 LLaMA-7B 架构设计,旨在能够在边缘设备上高效运行,无需将数据发送到远程服务器或云端处理。如智能手机、平板电脑、智能手表等。
MobiLlama 模型虽然体积小、对资源的需求低,但仍能提供高精度的语言理解和生成能力。
项目还提供了在安卓上运行 MobiLlama 模型的方法和安装包下载链接。https://mbzuaiac-my.sharepoint.com/:f:/g/personal/omkar_thawakar_mbzuai_ac_ae/EhRfGdmgFVVNvIRfy1EgLwEBjbk_eg3UmNg_zjz7PMTsmg?e=NBuJo8
主要能力:
1、高精度的语言理解与生成:即便参数规模相对较小(0.5 亿参数),MobiLlama 也能高效处理自然语言理解和生成任务,如文本摘要、问答系统、自然语言推理等。
2、轻量级设计:通过优化模型架构和采用参数共享技术,MobiLlama 实现了模型大小和计算资源需求的显著减少,使其适合在计算能力有限的设备上运行。
3、资源效率高:MobiLlama 在设计时考虑了能效和内存使用效率,使其在执行任务时消耗更少的电力和存储空间,适合长时间运行在移动设备上。
4、适应性强:由于其轻量级和高效的特性,MobiLlama 可以轻松集成到各种应用中,从智能助手到语言翻译工具,都能从其快速、精确的处理能力中受益。
-模型类型:基于 LLaMA-7B 架构设计的语言模型。 -语言/领域:主要针对英语 NLP 任务。 -全透明:MobiLlama 项目开源,提供了模型的训练数据、代码和训练过程的详细信息,使其他研究者和开发者可以完全了解模型的工作原理,有助于促进技术的进步和应用的开发。
MobiLlama 项目提供了不同配置的模型版本,包括 0.5B、0.8B、1B 及其聊天版本的模型。
0.5B:这个版本的模型有 0.5 亿参数,是设计中最轻量级的一个,旨在提供较高的效率和速度,同时保持良好的性能,特别适合在资源受限的设备上使用。
0.8B:0.8 亿参数的模型在 0.5B 的基础上增加了参数,以改进模型的性能和理解能力,适合于需要更复杂处理能力的场景。
1B:1 亿参数的模型进一步增强了模型的能力,能够处理更复杂的语言理解和生成任务,适用于对性能要求更高的应用。
数据集:
项目使用了预处理过的 Amber 数据集,总计约 1.2 万亿 token,数据来源包括 Arxiv、Book、C4、Refined-Web、StarCoder、StackExchange 和 Wikipedia 等,总大小约为 8TB。
评估结果:
基准测试性能
MobiLlama 模型在包括 HellaSwag、TruthfulQA、MMLU、ARC_C、CrowsPairs、PIQA、RACE、SIQA、WinoGrande 等测试中的性能表现,与其他模型进行了比较。在这些基准测试中,MobiLlama 表现出色,尤其是在 0.5B 和 0.8B 配置下,展现了其高效处理复杂语言任务的能力。具体的评估结果如下:
MobiLlama (0.5B):在多项任务中取得了优异的成绩,平均得分达到 46.00,突出显示了模型的高效率和准确性。 MobiLlama (0.8B):进一步提升了性能,平均得分达到 46.67,表明了通过增加模型规模可以进一步提升性能。 比较分析
与其他模型相比,如 GPT-NEO、TinyStarCoder、Cerebras-GPT 等,MobiLlama 在相同或更小的参数规模下,能够实现更高的准确度和效率。这些结果凸显了 MobiLlama 在设计上的优势,即通过参数共享和模型优化,实现了在资源有限的设备上运行高性能模型的目标。
具体性能对比 GPT-NEO (0.15B):平均得分为 40.93。 TinyStarCoder (0.17B):平均得分为 37.86。 Cerebras-GPT (0.26B):平均得分为 40.69。
MobiLlama 的性能优于这些模型,展现了其作为小型语言模型的竞争力和潜力。
模型下载:https://huggingface.co/MBZUAI
GitHub: https://github.com/mbzuai-oryx/MobiLlama
论文:https://arxiv.org/abs/2402.16840
在线体验:https://845b645234785da51b.gradio.live

5、从健身房到 SaaS 产品
推特上一位善于思考的朋友@AndrewBBoo 去了一趟健身房,被推销了一张健身卡,这引发了他的一系列思考。
原文:
昨晚去小区健身房踩点,本来只想了解下价位(不一定会长租),结果被拉着办了张 3 年的健身卡,服了。。复盘下别人怎么销售的,感觉好多套路都在 SaaS 产品中见过:
- 去前台问价格,绝口不提,先带我逛了一圈,详细介绍设施,什么多层减震的跑步机,花 400 万搭建过滤系统的室内恒温泳池,一周几节的免费团课。转完坐下来,拿出 Pad,竟然对着 PPT 给我讲了起来:什么企业文化、参照国外大酒店购置的器材、明星和这些器材的合照、团课课表、用户微信群的打卡,balabala。(被这一通 Landing Page 轰炸搞懵逼了,心里想这可能是我买不起的健身卡)
- 然后拿出宣传册,给我抛了个价格,年卡 6668。问了下月卡多少钱,说是先交 1999 的入会费,然后每个月 1000 元。(我知道了价格,准备开溜了)
- 我说刚搬到这边来,不一定会长租,等我过一两个月确定了长租,再考虑办年卡。然后对面就抛出了第一波折扣,说我可以先给你办个年卡,然后免费送你 3 个月,3 个月后如果决定在这边长租再激活卡,否则的话是可以自行免费转一次卡的,如果怕自己找不到下家,健身房也可以帮忙转卡,但通过健身房转要收 20% 手续费。(确实是针对我的理由的解决方案,但我不为所动,拒绝掉准备开溜)
- 这时,对面压低了声音,说他是这边的经理,可以以他的名义给我办张内部的亲友卡,但要我帮忙保密。亲友卡的价格是 5000 元 2 年,还可以通过内部员工的转卡通道,免手续费健身房帮忙找下家转卡。(有点心动了,我拿出手机翻了下闲鱼,发现 有人 3500 转让这个健身房 18 个月的卡,但考虑到我不一定会租这么久,感觉他在套路我,再次准备开溜)
- 最后,他摊牌了,说你以后如果不需要健身房帮你转卡而是自己联系,我是经理,做主再给你个优惠,5000 元 3 年的内部员工亲友卡,免费转卡一次,就算一天不来,直接转手加价 2000 卖出去也是不亏的,我就是为了新年开单,亲友卡名额有限留不了,你不买的话,我就给下个客户了。(然后,我一个附近租房的人,成为了健身房 3 年 VIP。。3 年,就算我还在,不知道这个健身房还在不在😱)
- 他去拟定合同过程中,又给我找了个健身主管,给我测体脂等指标,给了很多健身建议,最后说要免费送一节私教体验课。(我这次终于成功拒绝了一回🌝)
唉,这销售能力,我中途拒绝了好多次准备开溜,硬是被拉下来了。回想下比较眼熟的套路:
- 进去咨询本身就是精准用户(感觉像是 SEO 搜索流量)
- 内容丰富的 Landing Page(之前看@levelsio 的 twitter 有讨论,Landing Page 内容丰富,尤其是包含媒体和用户的评价,可能并不简洁美观,但对付费转化是有利的)
- 价格锚定(初始的高价和亲友卡折扣价对比,以及年费价格和月费价格的对比)
- 未转化用户的召回(注册但未一段时间未付费用户,邮件赠送折扣码)
- 如何进行折扣(较好的方案是不要改价格,而是相同的价格,给对方更多的额度;同时,折扣给个 deadline)
- 如何挖掘用户更多的付费需求(像这边的健身私教课,可以是自己的其他相关产品,也可以是分销)
- 以及最最重要的,要解决用户的痛点问题/给用户带来价值(回想下我愿意持续付费的产品,都是我感觉给我带来的收益远大于订阅费的,比如 Perplexity, Vercel Pro 等,一些新奇好玩的痒点产品,即便付费了也不会复购,而健身卡一方面是对健康的投资,另一方面其具有转卡价值)
最近复盘了下自己尝试的几个网站,流量最终是靠付费产品去承接的(自己的或别人的),而不同商业化方式漏斗并不相同,Google Adsense 只是收个过路费,Affiliate 虽然有较高的分成比例,但往往是针对新用户的(我之前做的阿里云幻兽帕鲁服务器分销,付费的大概仅有 1/7 是新用户,大量的老用户订单只是单纯为阿里贡献流量),最为高效的转化还是要有个自己的付费产品。回顾我自己做的几个产品,解决的并非用户的痛点问题,也无法为用户持续创造经济价值,自然难以吸引留存及付费转化,感觉后面要调整下方向。
想到哪写到哪,最后推荐一本过年期间读的书吧 https://saasplaybook.com,里面讲了 SaaS 产品的商业模式,几个有效提升流量/营收的策略(书中称为 Cheat Code),以及一些定价相关的内容,正好是我当下需要的,实践下看看。

6、AFFiNE:本地的开源 Notion + Miro 解决方案
- 调研:在 AFFiNE 画板中自由粘贴链接,视频以及编辑文档,提炼精华内容
- 总结:画板中总结精华内容一键转换成文档
- 演示:写完文档可以直接转成 PPT 模式演示
Github 链接:https://github.com/toeverything/AFFiNE
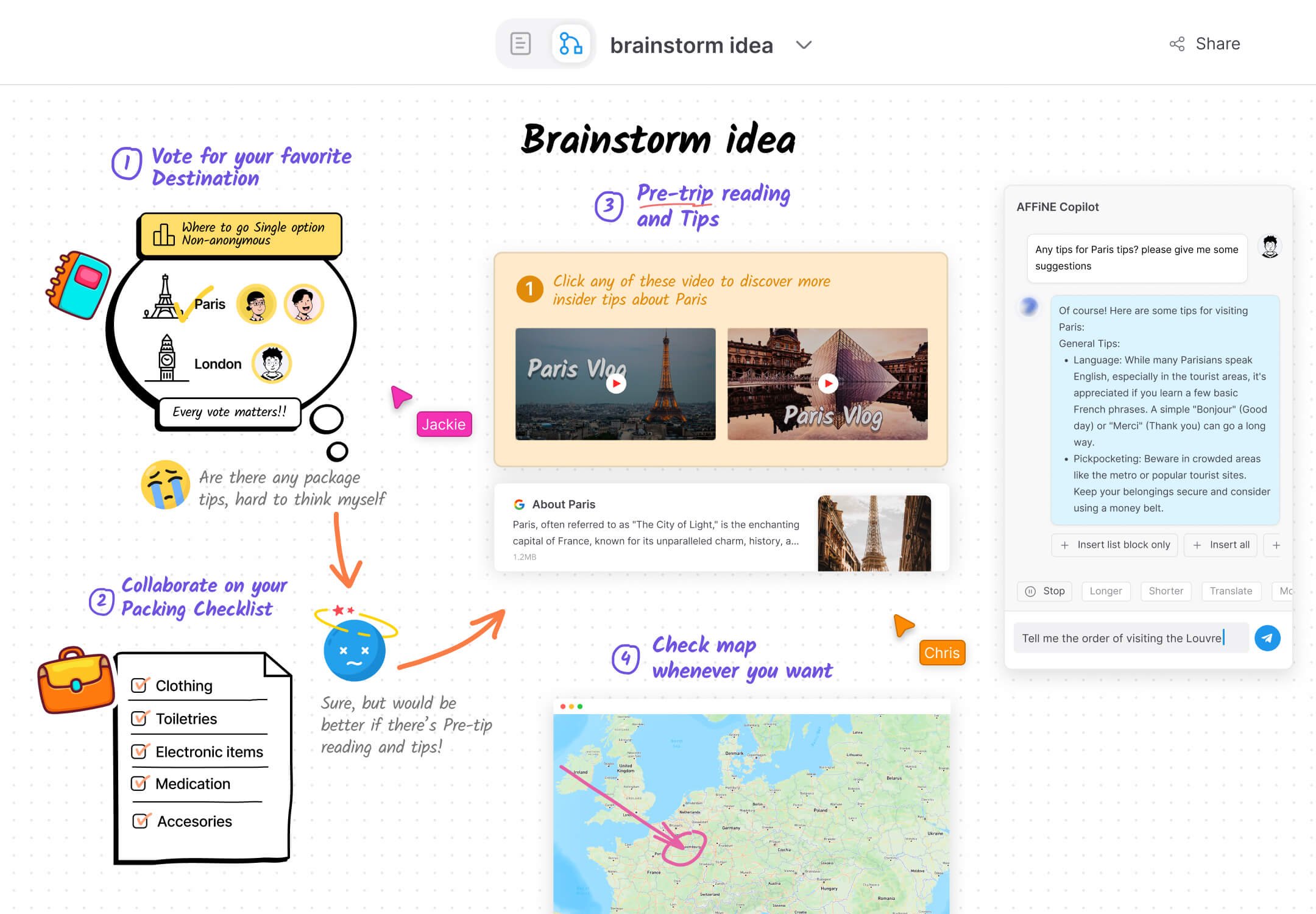
虽然 Miro(可视化协作平台)和 Notion(笔记工具)使用起来非常流畅且功能强大,但它们并不是开源解决方案。那么,更私密、更透明、更可定制、可用于 Windows/OS/Linux 的下一代知识库是否存在呢?这就是 AFFiNE!
与专注于白板和页面的 Miro 和 Notion 不同,AFFiNE 将其定位定义为一体化的 KnowledgeOS。它支持看板、表格和富文本段落作为构建块来形成页面或白板,可以在这里进行文档编辑、数据处理或头脑风暴等综合处理。
AFFiNE 使用 Rust 和 Typescript 构建,只需要一个命令即可运行整个项目,AFFiNE 以最简单的方式给了所有开发者最大的想象力。
7、微软最新研究:不经过训练直接融合多个 Lora 不损失效果
项目介绍:
本项目旨在通过新的文本至图像生成方法,着重采用多重低秩适应(Low-Rank Adaptations, LoRAs)技术,创造高度个性化且细节丰富的图像。我们介绍了 LoRA 开关(LoRA Switch)与 LoRA 组合(LoRA Composite),这两种方式的目标是在精确度和图像质量上超越传统技术,特别是在处理复杂图像组合时。
项目特色:
🚀 免训练方法 LoRA 开关和 LoRA 组合支持动态精确地整合多个 LoRA,无需进行微调。 我们的方法不同于那些融合 LoRA 权重的做法,而是专注于解码过程,并保持所有 LoRA 权重不变。
📊 ComposLoRA 测试平台 这是一个全新的综合性测试平台,包含 480 套组合和 22 个在六大类别中预训练好的 LoRA。 ComposLoRA 专为评估基于 LoRA 的可组合图像生成任务而设计,支持定量评估。
📝 基于 GPT-4V 的评估工具 我们提出采用 GPT-4V 作为评估工具,用以判定组合效果及图像质量。 该评估工具已证实在与人类评价的相关性上有更好的表现。
🏆 卓越性能 无论是自动化还是人类评价,我们的方法都显著优于现有的 LoRA 合并技术。 在生成复杂图像组合的场景中,我们的方法表现出更加突出的优势。
🕵️♂️ 详尽分析 我们对每种方法在不同场景下的优势进行了深入的分析。 同时,我们还探讨了采用 GPT-4V 作为评估工具可能存在的偏差。
项目地址:https://maszhongming.github.io/Multi-LoRA-Composition/
8、Morph Studio 与 Stability AI 合作
Morph Studio 推出了一款与 Stability AI 合作的 AI 电影制作平台,该平台通过利用 AI 生成的视频片段,改变了电影制作的方式。该平台采用故事板格式,允许用户通过文本提示来创建和编辑场景,从而便于创造一个统一的叙述。这一创新基于 Morph Studio 与 Stability AI 的合作,Morph 计划扩展用户可选择的生成视频模型范围。平台强调了一个无缝的制作流程,用户可以在 Morph 的创作者社区分享他们独特的生产流程,其他人可以通过更改 AI 提示来复制和修改模板。Morph 的联合创始人 Xu Huaizhe 表示,AI 将传统电影制作的拍摄、编辑和后期制作等分离步骤转变为一个连续的过程。Morph Studio 由一组来自香港科技大学的计算机视觉博士辍学生在 2023 年创立,Xu 将 CapCut 视为潜在的竞争对手,并致力于确保其创业公司不会轻易被其他公司替代。Xu 认为,构建一个活跃的用户社区将是 Morph 的优势之一,他还指出 Morph 在技术上做出了巨大努力,以更好地满足创作者的需求。
waitlist: https://app.morphstudio.com/waitlist
9、工具推荐:腾讯做了一个在线工具箱
里面有非常多实用的小工具,而且还是免费的,也不需要登录。 https://tool.browser.qq.com
10、软件推荐:LocalSend
是一个免费、开源的应用程序,允许你在本地网络上安全地与附近设备共享文件和消息,无需互联网连接。 https://localsend.org https://github.com/localsend/localsend
11、资料推荐:认知偏差知识手册
https://s75w5y7vut.feishu.cn/docs/doccn3BatnScBJe7wD7K3S5poFf

12、课程推荐:Prompt Engineering with Llama 2
课程地址:https://www.deeplearning.ai/short-courses/prompt-engineering-with-llama-2
Deeplearning.ai 与 Meta 合作推出了新短期课程“Llama 2 提示工程”。
这门课程旨在帮助提高提示工程技能,学习在使用 Llama 2 模型集合构建应用程序时,提示的最佳实践。
Llama 2 模型及其模型权重可以免费下载,包括可以在您的本地机器上运行的量化模型版本。通过一个简单的 API 调用与这些模型进行交互,并探索不同模型在各种任务中输出的差异。