 第06期 - 哈佛大学机器学习
第06期 - 哈佛大学机器学习

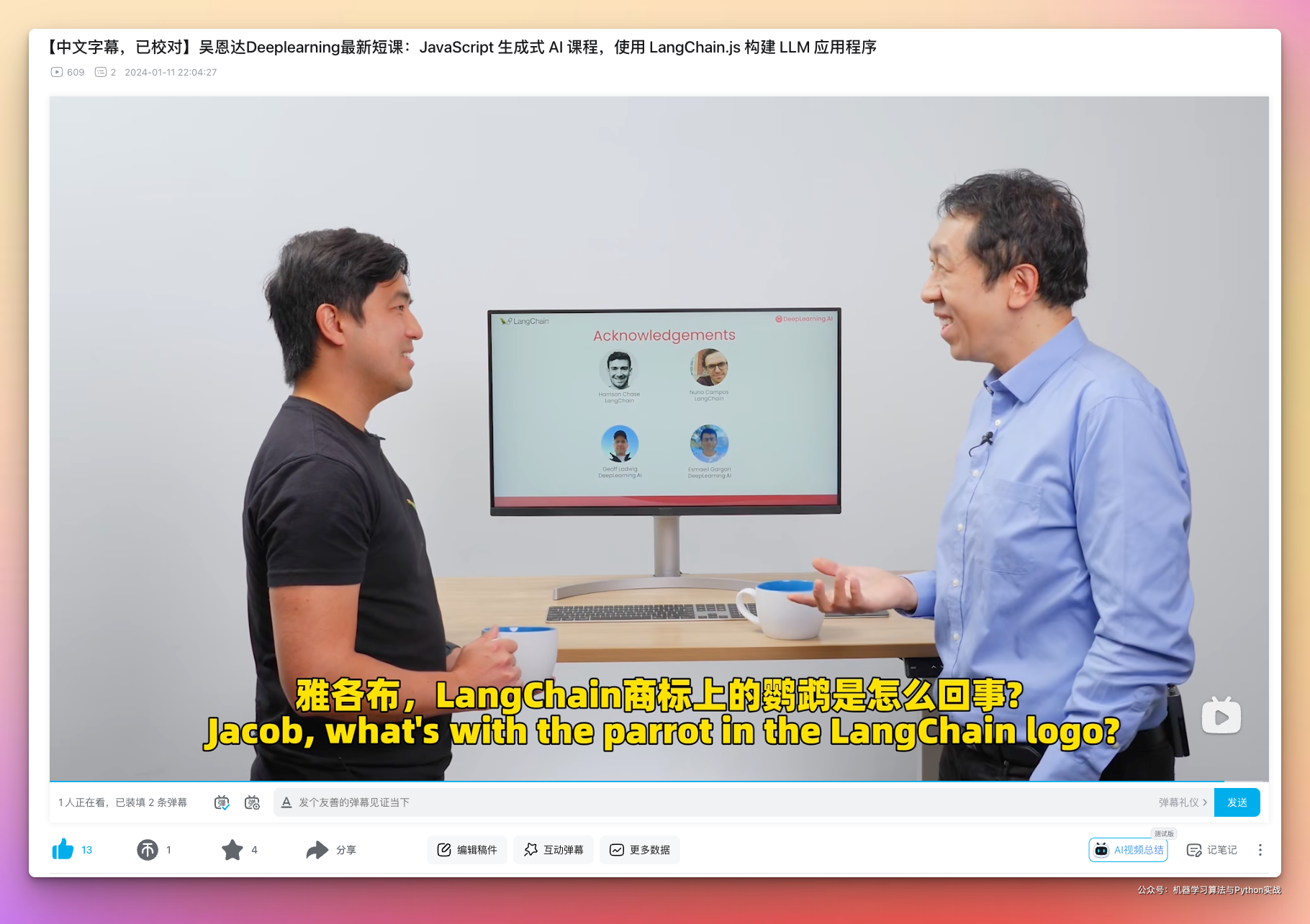
吴恩达和 Langchain 合作开发了 JavaScript 生成式 AI 短期课程:《使用 LangChain.js 构建 LLM 应用程序》
大家好,欢迎收看第六期Ai周刊
本期介绍 10 个内容,涉及Python、机器学习、大模型等,目录如下:
- 1、哈佛大学机器学习课
- 2、第一个 JavaScript 生成式 Al 短期课程
- 3、一个地理相关的 Python 库
- 4、电脑本地运行大模型聊天软件,支持中文
- 5、Chatbot Ul 2.0 发布
- 6、文本嵌入的 74 年历史
- 7、LangChain v0.1.0 发布
- 8、一个由 Google 开发的机器学习工具
- 9、Mixtral 8x7B 论文发布
- 10、斯坦福大学开发出一个几乎不会产生幻觉的模型:WikiChat
1、哈佛大学机器学习课
课程简介:https://pll.harvard.edu/course/data-science-machine-learning
注册地址:https://www.edx.org/learn/machine-learning/harvard-university-data-science-machine-learning

首先强烈推荐一下质量上乘,完全免费的哈佛大学机器学习课程,
2024 年度课程开始了,目前有两个时段可选
-
1 月 9 日到 6 月 20 日
-
4 月 18 日到 12 月 19 日
授课老师是哈佛大学生物统计学教授拉斐尔·伊里扎里,感兴趣可以去 edX 注册了
2、第一个 JavaScript 生成式 AI 短期课程!
地址:https://deeplearning.ai/short-courses/build-llm-apps-with-langchain-js/
吴恩达和 Langchain 合作开发了 JavaScript 生成式 AI 短期课程:《使用 LangChain.js 构建 LLM 应用程序》
课程简介如下:
GitHub 最近报告称 JavaScript 再次成为世界上最流行的编程语言。为了支持 Web 开发人员探索和开发生成式 AI,我们刚刚推出了一个新的 JavaScript 短期课程,由 @LangChainAI 的创始工程师 @Hacubu 教授。在使用 LangChain.js 构建 LLM 应用程序中,您将学习人工智能开发中常见的元素,包括:
(i) 使用数据加载器从 PDF、网站和数据库等常见来源提取数据 (ii) 提示,用于提供 LLM 上下文 (iii) 支持 RAG 的模块,例如文本分割器以及与向量存储的集成 (iv) 使用不同的模型来编写不特定于供应商的应用程序 (v) 解析器,提取并格式化输出以供下游代码处理
我对这门课非常感兴趣,但是 deeplearning 官网还没有字幕,学起来非常困难
已经有 up 搬运并配了机翻字幕,但是感觉很多地方翻译的不是很准确
所以我准备一边学习一边翻译并上传,但是这个字幕翻译工作还是蛮费功夫的,可能进度不会很快
感兴趣的同学可以关注一下:https://www.bilibili.com/video/BV1Te411m7ys
3、一个地理相关的 Python 库
地址:https://gist.github.com/alexgleith/dc49156aab4b9270b0a0f145bd7fa0ce
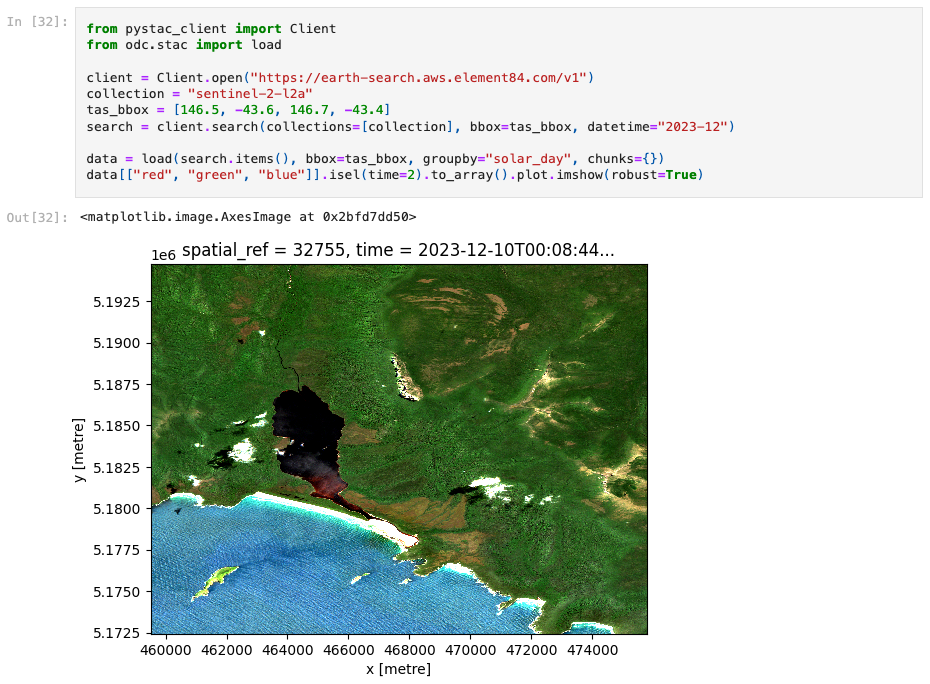
推荐一个地理相关的 Python 库:
2 个 Python 库、6 行代码和大约 15 秒的时间,就可以从世界任何地方加载卫星数据
4、电脑本地运行,大模型聊天软件,支持中文
地址:https://github.com/janhq/jan
官网:jan.ai/

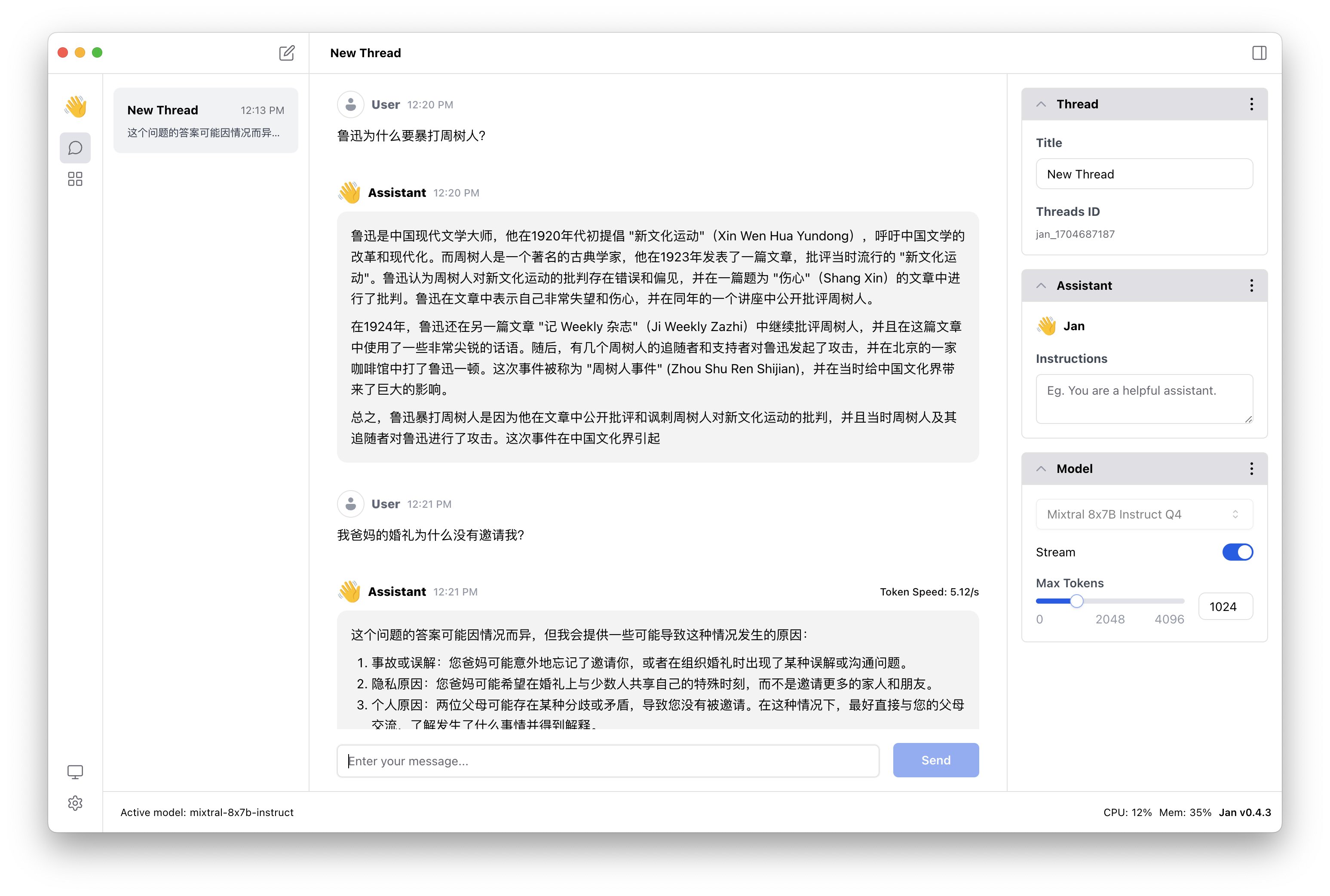
Jan 是 ChatGPT 的一个开源替代品,最近在 GitHub 上非常火爆。它能够在电脑上 100% 离线运行,支持 Nvidia GPU & Apple M。
提供众多开源 AI 模型下载,每次对话选择一个模型后自动切换,很方便。
Jan 能在任何硬件上运行,从个人电脑(Linux、Windows、MacOS)到多 GPU 集群,Jan 支持通用架构:
- Nvidia GPUs (快速)
- Apple M 系列 (快速)
- Apple Intel
- Linux Debian
- Windows x64
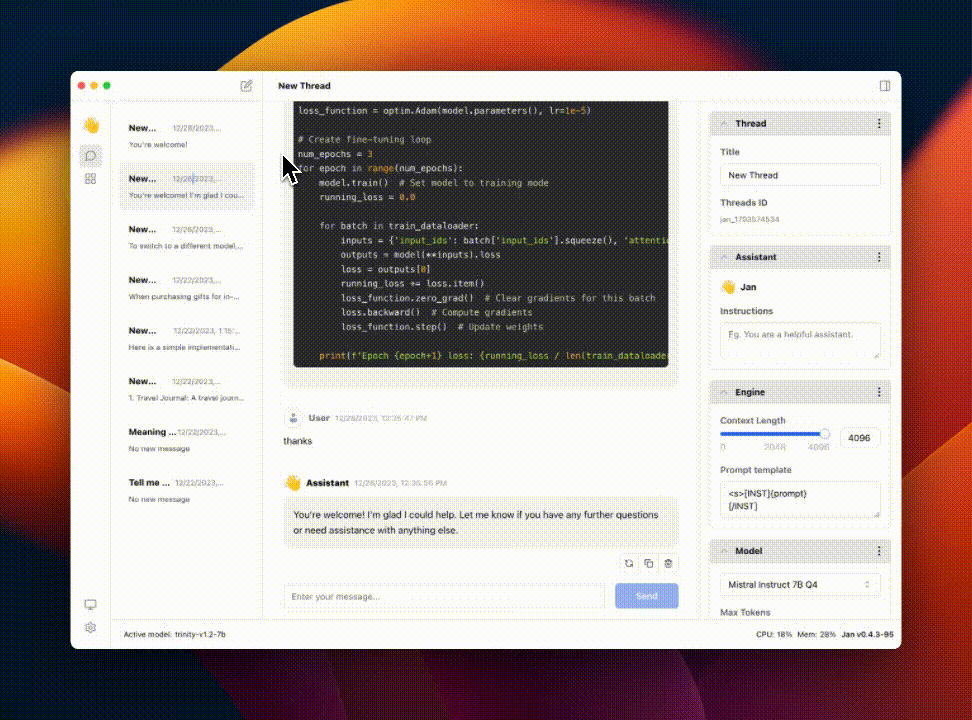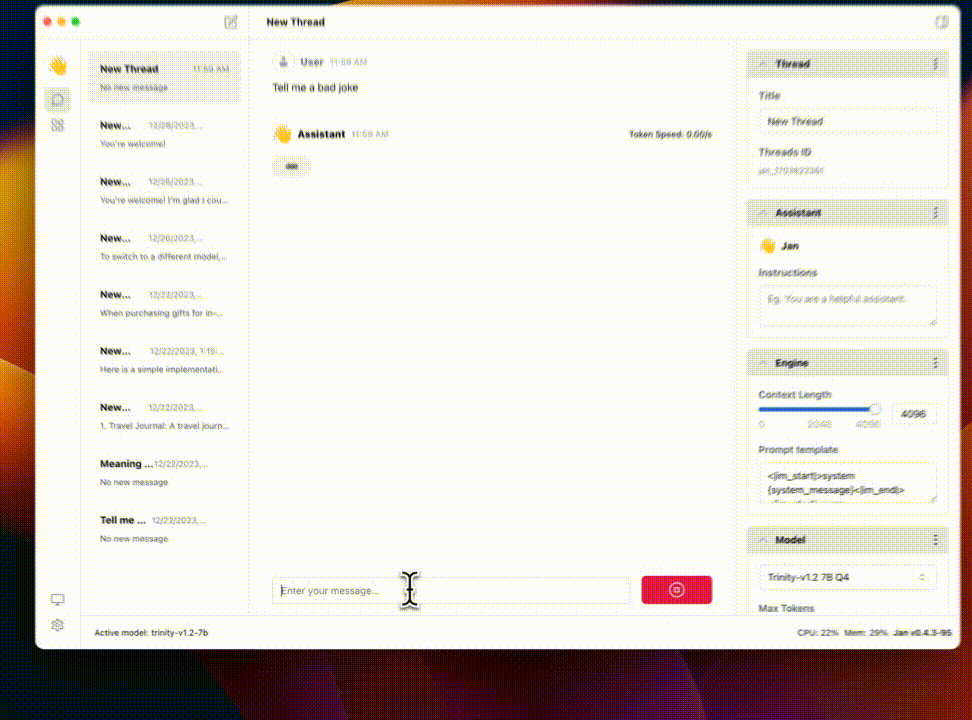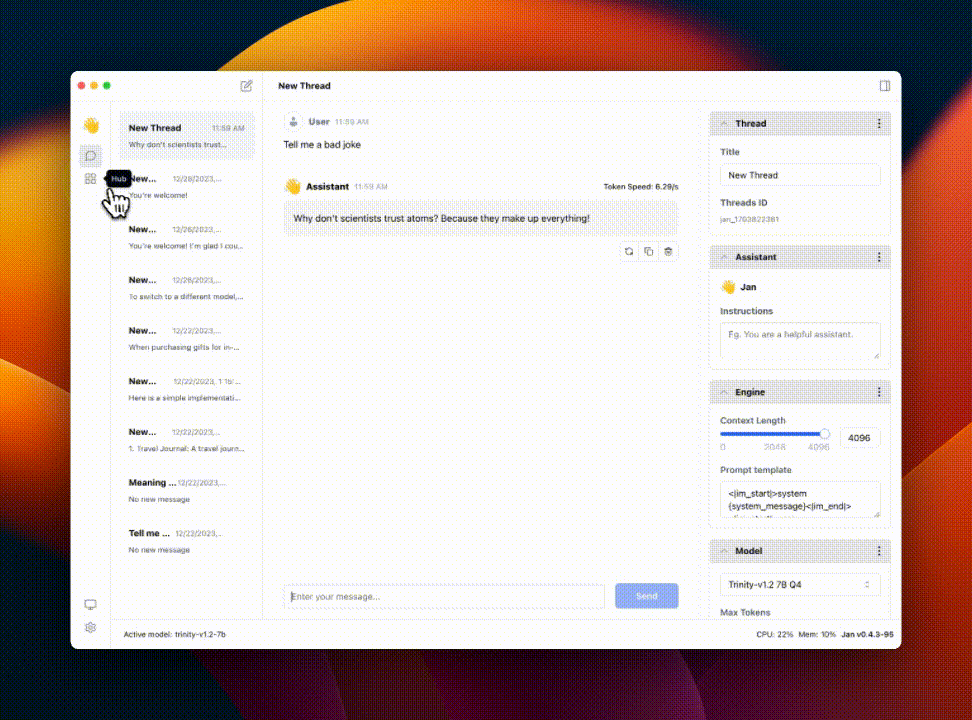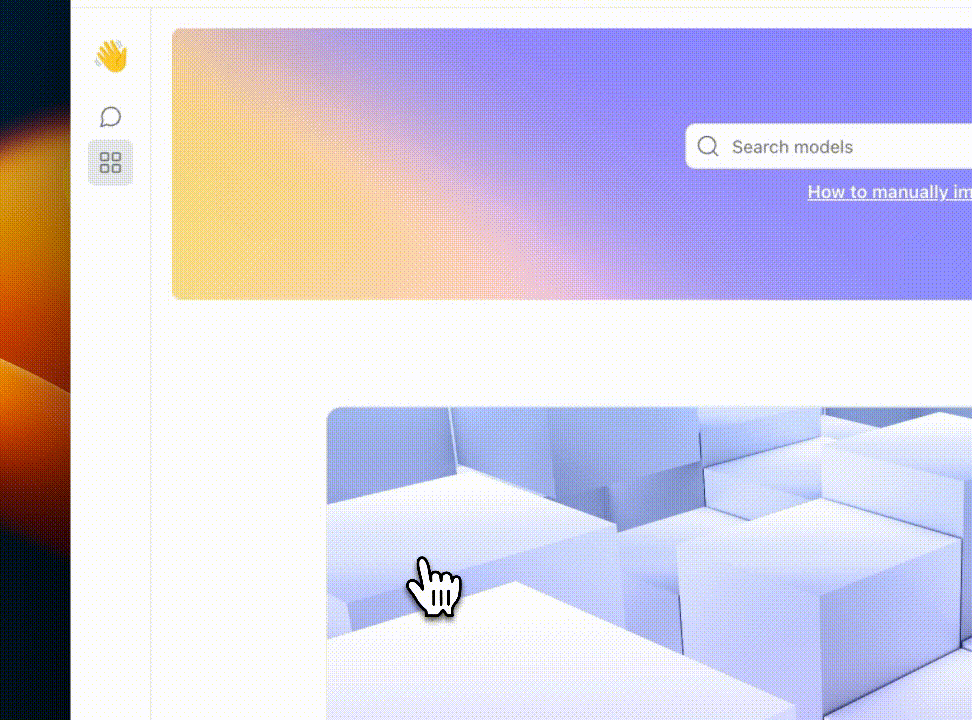
有 X 友做了测试,支持中文,效果不错
5、Chatbot UI 2.0 发布
地址:https://github.com/mckaywrigley/chatbot-ui
最近 Chatbot UI 2.0 发布了,这是一个面向所有人的开源 AI 聊天界面。
它不仅支持 OpenAI、Claude 的 API,还支持 Gemini、Mistral、Perplexity API、本地 Ollama 安装的模型。
目前 Google 的 Gemini API 是免费了,感兴趣可以申请后结合这个工具使用。
关于 Gemini,我之前写过一篇文章,详细地介绍了玩法:叫板 GPT-4 的 Gemini,我做了一个聊天网页,可图片输入,附教程

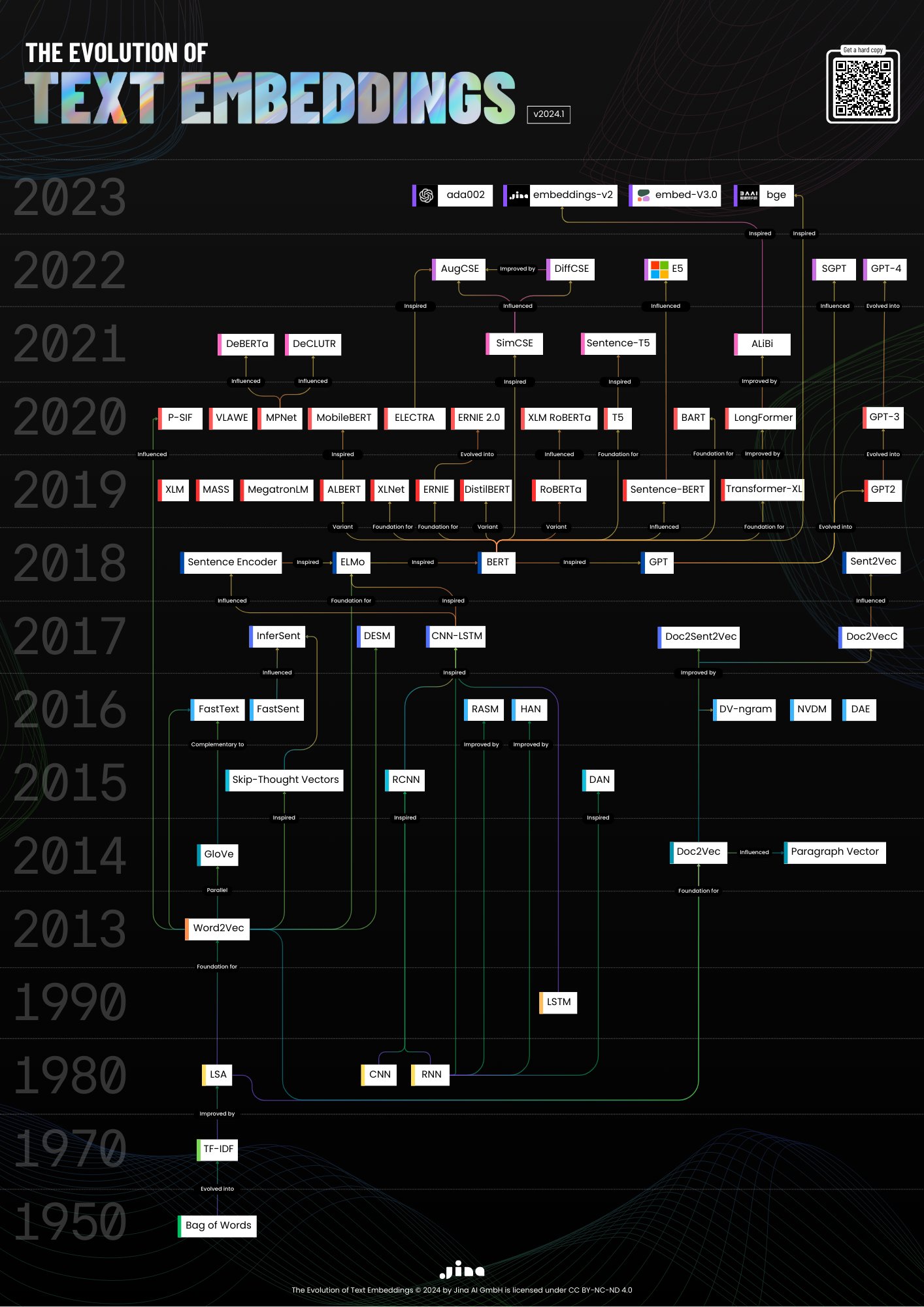
6、文本嵌入的 74 年历史
地址:https://jina.ai/news/the-1950-2024-text-embeddings-evolution-poster/
JinaAI 绘制的这张高清 PNG 海报记录了文本嵌入自 1950 年至今的历史,展示过去 74 年的突破性演变。
网页中还提供了丰富的参考资料,每个技术里程碑都附带一个可供探索的资源列表。
7, LangChain v0.1.0
地址:https://blog.langchain.dev/langchain-v0-1-0/
LangChain 是大模型世界最重要的工具之一,本周 LangChain 发布了 0.1 稳定版,完全向后兼容,同时提供 Python 和 JavaScript,并在功能和文档方面都进行了改进。
👀 可观察性:构建复杂的 LLM 应用程序很困难。为了最好地进行调试,需要知道所采取的确切步骤以及每个步骤的输入/输出。通过与 LangSmith 的紧密集成,LangChain 拥有一流的可观察性
↔️ 集成:近 700 个集成,无论你想使用什么技术堆栈,LangChain 都支持
🔗 可组合性:使用 LangChain 表达式语言,可以轻松(且有趣!)创建任意链,为您带来数据编排框架的所有优势
🎏 流式传输:我们投入了大量资金来确保使用 LangChain 表达式语言创建的所有链以一流的方式支持流式传输 - 包括中间步骤的流式传输
🧱 输出解析:让 LLM 以某种格式返回信息是使其执行操作的关键。
🔎 检索:为 RAG 添加先进且可用于生产的方法,包括文本分割、检索和索引管道
🤖 工具使用 + 代理:代理集合(决定采取什么操作),工具集合,定义工具的简单方法

8、Teachable Machine:一个由 Google 开发的机器学习工具
地址:https://teachablemachine.withgoogle.com
Google 开发机器学习工具 Teachable Machine,它允许用户快速、简单地创建自己的机器学习模型,而无需专业知识或编程技能。
你可以用它来教电脑识别图片、声音或人的动作。
使用这个工具的步骤很简单:
1、收集数据:你可以上传图片、录制声音或动作视频来作为训练数据。
2、训练模型:用这些数据来训练你的模型,然后测试它能否正确识别新的图片、声音或动作。
3、导出模型:完成训练后,你可以下载这个模型,或者上传到网上,用在其他项目中。
Teachable Machine 提供了多种方式来创建机器学习模型,非常灵活和用户友好。
1、使用文件或实时捕捉示例:用户可以选择上传已有的图片、音频文件作为数据,也可以直接通过电脑的摄像头或麦克风实时录制视频、声音作为训练数据。
2、可以在本地完成训练:用户有选项不通过网络发送或处理数据。所有操作,包括数据的收集、模型的训练和应用,都可以在用户自己的电脑上完成,不需要将摄像头或麦克风收集的数据发送到互联网上。这对于隐私保护是非常重要的,特别是当处理敏感信息时。
3、Teachable Machine”生成的模型是真实的 TensorFlow.js 模型,可以在任何运行 JavaScript 的地方工作。此外,还可以将模型导出到不同的格式,以便在其他地方使用,如 Coral、Arduino 等。
9、Mixtral 8x7B 论文发布
论文:https://arxiv.org/abs/2401.04088
Mixtral 官网关于 MoE 的介绍:https://mistral.ai/news/mixtral-of-experts/
本周另一个在 X 上刷屏的事件(前一个是 LangChain v0.1.0 的发布)是 Mixtral 8x7B 论文发布。
Mixtral 模型发布已经一个月了,Mixtral 8x7B 如此令人兴奋的原因在于它探索了一种新的架构范例,即“专家混合”方法,与大多数 LLMs 所遵循的方法形成鲜明对比。尽管这种方法并不新鲜,但尚未在 LLM 领域得到大规模证明。然而,Mixtral 论文表明,Mixtral 8x7B 在各种基准测试中与更大的模型(例如 Llama 2 70B 和 GPT-3.5)相比具有良好的性能。
什么是专家混合 (MoE) 方法?
MoE 方法是一种机器学习技术,结合了多个专家模型的优势来解决问题。与结合所有模型结果的集成技术相比,在 MoE 中,仅使用一名或少数专家来进行预测。
这种方法有两个主要组成部分: • 路由器:决定对于给定输入信任哪个专家以及如何权衡每个专家对于特定输入的结果。 • 专家:专门研究问题不同方面的个体模型。
在 Mixtral 的案例中,有八位专家,其中两位是被选中的。


10、斯坦福大学开发出一个几乎不会产生幻觉的模型:WikiChat
GitHub:https://github.com/stanford-oval/WikiChat 论文:https://arxiv.org/abs/2305.14292 在线体验:https://wikichat.genie.stanford.edu
大模型的通病是幻觉问题,也即一本正经地胡说八道。来自斯坦福的研究人员发布了 WikiChat——被称为首个几乎不产生幻觉的聊天机器人!
WikiChat 基于英文维基百科信息,当它需要回答问题时,会先在维基百科上找到相关的、准确的信息,然后再给出回答,保证给出的回答既有用又可靠。
模型在新的基准测试中获得了 97.3% 的事实准确性,而相比之下,GPT-4 的得分仅为 66.1%。
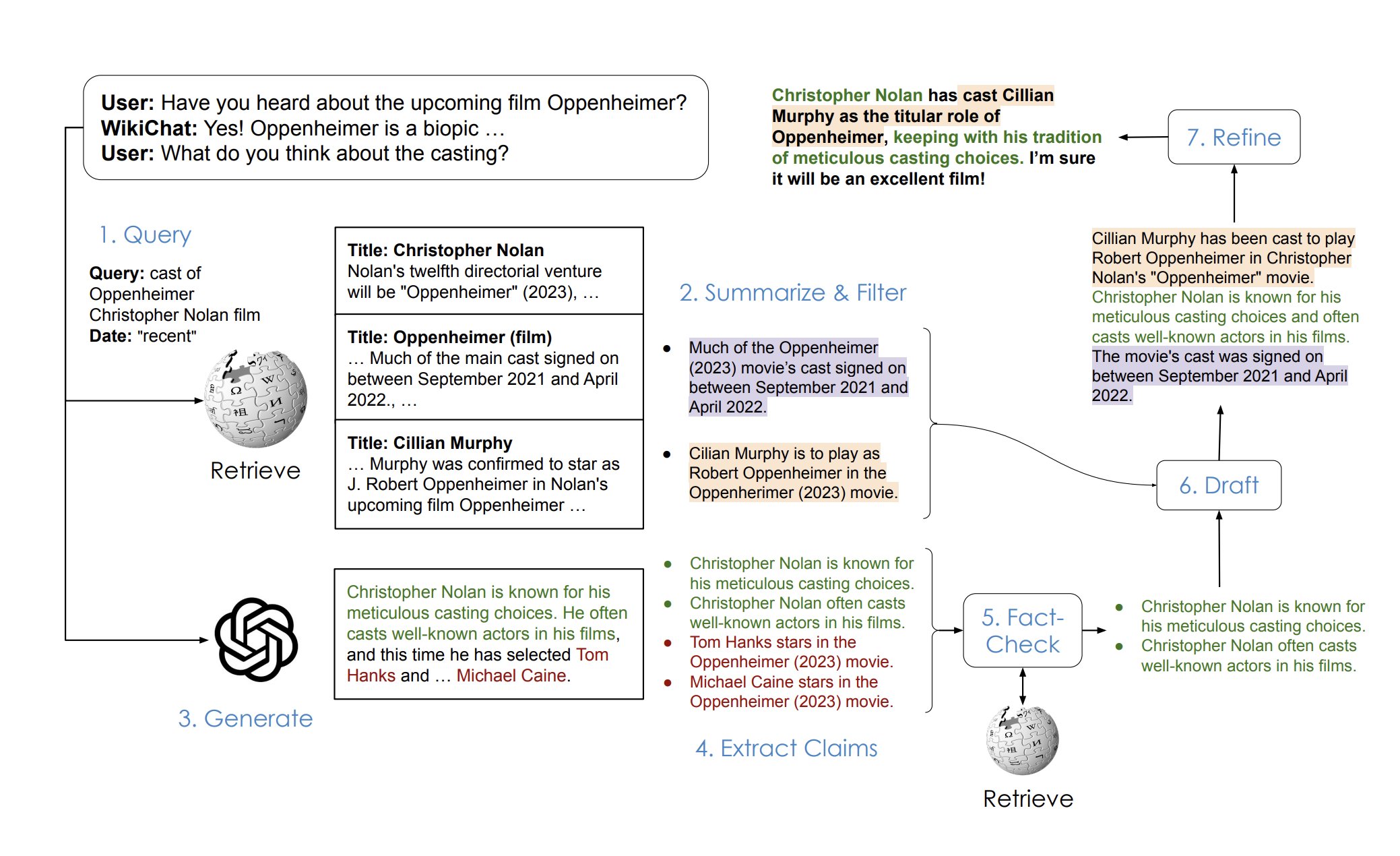
这个模型可以在线体验,不过遗憾的是它不支持中文,而且试用次数非常有限。
顺便说一句,斯坦福不但开源了模型,还开源了上面这个聊天应用 ovalchat 的代码:
https://github.com/stanford-oval/ovalchat
