 第08期 - 斯坦福大学小黄鸭
第08期 - 斯坦福大学小黄鸭

这个项目每周更新机器学习、人工智能领域最新、最热门的论文**
1、哈佛大学 CS50 小黄鸭
来自斯坦福大学的 CS50 小黄鸭,一个能够通过多个平台回答课程相关问题的聊天机器人。
CS50 小黄鸭的名字来源于小黄鸭调试法(一种调试代码的方法,耐心地向一只小黄鸭解释每一行程序的作用,以此来激发灵感与发现问题),它可以类似于 ChatGPT 聊天,也可以自动回复论坛上的学生提问,还可以作为 VSCode 插件辅助编程。
CS50 小黄鸭通过一个可视的爱心计数器来限制使用频率。每位学生初始有 10 颗爱心,每隔三分钟可以恢复一颗。每次与 CS50 小黄鸭互动都会消耗一颗爱心,这样可以防止滥用行为。
我试了一下,GitHub 账号登陆即可,支持中文,效果还行吧

2、大学考试问题的多模态数据集
🌐 Homepage | 🤗 Paper | 📖 arXiv | 🤗 Dataset | GitHub

中文 LLM 评估新基准:CMMMU 中国大规模多学科多模态理解基准,包含 12k 手动收集的多模态问题。
CMMMU 是大学考试问题的多模态数据集,可通过 @huggingface Hub 获取: • 🧠 12k 个手动收集的多模式问题 • 🌐 涵盖 30 个主题和 39 种图像类型 • 📈 学术问题理解中人工智能模型的基准
3、每周机器学习论文精选
网址:https://github.com/dair-ai/ML-Papers-of-the-Week
这个项目每周更新机器学习、人工智能领域最新、最热门的论文
附了论文摘要和直达链接
4、一张图片,个性化图像合成
代码:https://github.com/InstantID/InstantID
试玩:https://instantid.org/#playground
只使用一张图片,就可以提取人脸,用于个性化图像合成,并支持各种不同的风格
我玩了几下,感觉蛮有意思的,效果还算满意。获取到 GPU 资源后大概 30-40 秒生成一张


5、OpenAI 重大更新
详情查看:https://openai.com/blog/new-embedding-models-and-api-updates
OpenAI 迎来几个更新,要点如下:
1、推出 text-embedding-3-small 和 text-embedding-3-large 全新 Embedding 模型,前者体积小、效率高、价格低,后者性能强大
2、新版且价格下调 50% 的 GPT-3.5 Turbo
3、最新的 GPT-4 Turbo 预览版 gpt-4-0125-preview,传言修复了模型变笨的问题
4、免费、强大的内容审核模型 text-moderation-007
6、傅盛:我们对做大模型没有执念,对做好应用有执念
链接:https://mp.weixin.qq.com/s/TdP82TDFCWyEZ79FuQKhSw
傅盛在猎户星空百亿大模型发布会上的演讲。
傅盛认为,企业要想真正用好 AI,必须全流程、全数据化,实现“数字老板”。对做大模型没有执念,对做好应用有执念,通过 AI 应用把大模型的能力和企业实际业务相结合,从而提供决策支持,助力企业达到王者段位。
傅盛预测,到 2024 年,千亿大模型中过半都会凋零,而百亿大模型会百花盛开。超越 OpenAI 的机会,将来自大模型应用公司。
傅盛的猎户星空发布了 Orion-14B 系列 LLM 模型,模型页面的测试挺全面的,主要特点有:模型整体多语言能力强,比如日语和韩语。支持超过 200k 的上下文。量化版本模型大小缩小 70%,推理速度提升 30%,性能损失小于 1%。Orion-14B 系列一共包含了 7 个不同的模型:基座模型、对话模型、长上下文模型、RAG 模型、插件模型、两个量化模型。
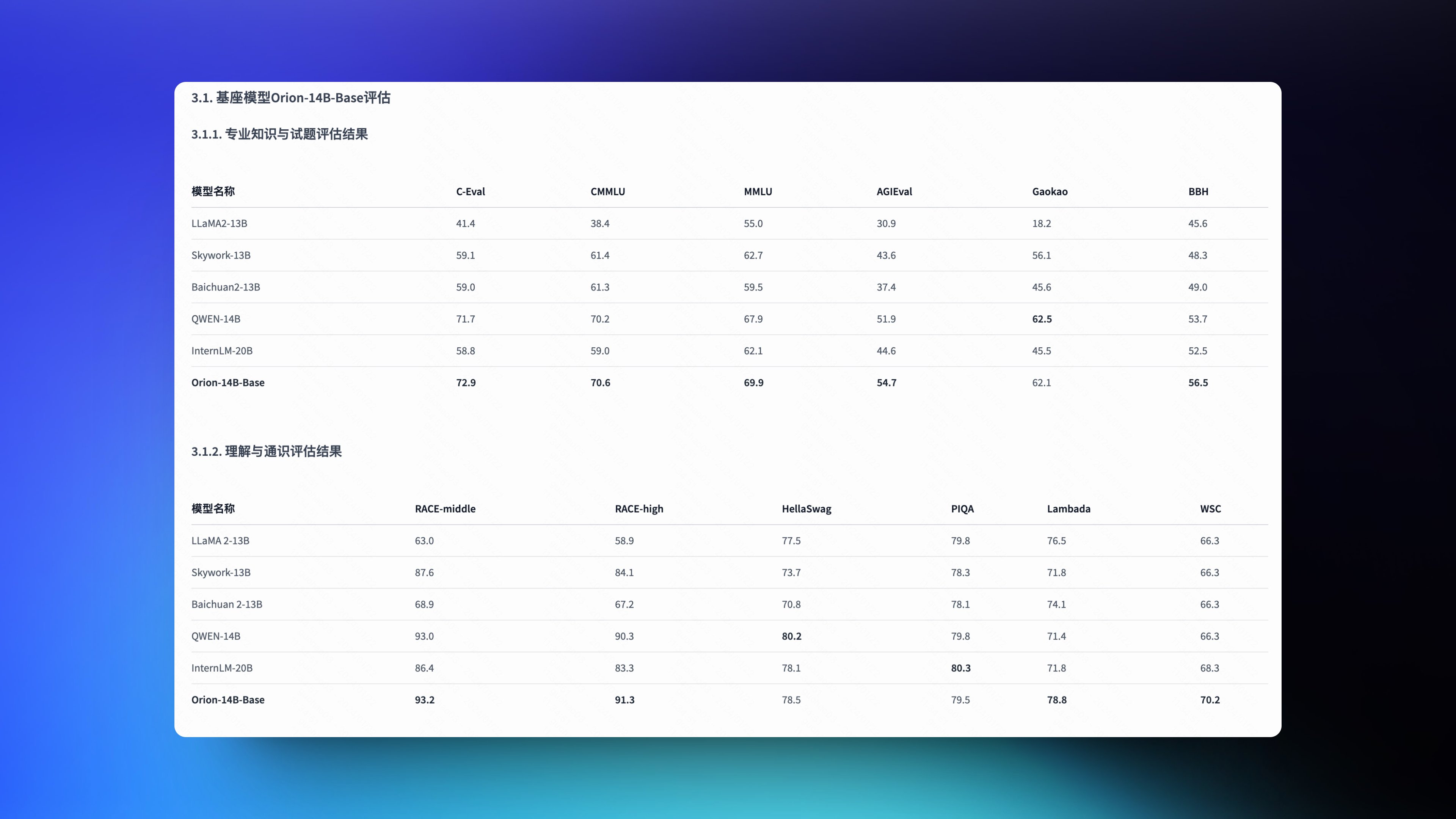
模型介绍页面:https://huggingface.co/OrionStarAI/Orion-14B-Chat-Int4/blob/main/README_zh.md…
7、Lumiere:一次性生成整个视频
项目及演示:https://lumiere-video.github.io
论文:https://arxiv.org/abs/2401.12945

Google Research 团队开发的基于空间时间的文本到视频扩散模型。
它采用了创新的空间时间 U-Net 架构,能够一次性生成整个视频的时间长度,不同于其他模型那样逐帧合成视频。
确保了生成视频的连贯性和逼真度。
支持文本到视频、图像到视频、风格化视频生成、视频编辑等
主要功能特点:
1、文本到视频的扩散模型:Lumiere 能够根据文本提示生成视频,实现了从文本描述到视频内容的直接转换。
2、空间时间 U-Net 架构:与其他需要逐步合成视频的模型不同,Lumiere 能够一次性完成整个视频的制作。这种独特的架构允许 Lumiere 一次性生成整个视频的时间长度,不同于其他模型那样逐帧合成视频。
3、全局时间一致性:由于其架构的特点,Lumiere 更容易实现视频内容的全局时间一致性,确保视频的连贯性和逼真度。
4、多尺度空间时间处理:Lumiere 通过在多个空间时间尺度上处理视频来学习直接生成视频,这是一种先进的方法。
5、风格化视频生成:使用单个参考图像,Lumiere 可以按照目标风格生成视频,这种能力在其他视频生成模型中较为罕见。
6、广泛的内容创作和视频编辑应用:Lumiere 支持多种内容创作任务和视频编辑应用,如图像到视频、视频修补和风格化生成。
8、一份详尽的《英语学习指南》,
在线阅读:https://byoungd.github.io/English-level-up-tips/

作者:离谱,介绍了学习英语的“小”技巧,分为认知篇、单词篇、听力篇、阅读篇、口语篇等
我看了认知篇,其中的方法论非常棒,不限于学英语。
